
Impression about Kotlin Coroutines
Last year during "Covid 1" I had 5-6 months activity with Kotlin Coroutines when I created an Android app which takes and pre-processes pictures for images classification Neural Networks training.
The following project overview is about what you can squeeze out of your mobile phone if you are really serious about using your expensive piece of hardware to reduce your cloud servers costs.
Using your employees Android phones for massive calculations
Your employees are carrying around powerful computers with 8 cores and 8 gigabytes of the memory which some 10 years ago were considered to be quite cool servers. Even today such a cloud node costs a little. And, imagine the costs of 100 such nodes...
The more your workers use their mobile phones to process the data, the less the cloud costs in your company.
As the Apple literally ruined background mode in the mobile apps many many years ago, Android with its WorkManager is the only option to create such predictable distributed calculations clusters on your employees mobile phones.
Project essence
Cool Tensorflow tutorials level programmers usually tell that they can train neural networks with just “2 lines of the code”.
But what if you need YOUR dataset, and with images of size 600x600, for example?
Or you cannot trust public datasets because of the Hackers?
I would risk saying that those now frequent Tesla crashes could suffer more from this than the other reasons. But it's only speculation. Another speculation is based on how the people test the whole dataset and ignore individual failures, as the average accuracy percentage is so good... When some single picture from the testing set could be totally misinterpreted.
I created an Android app to take my own Neural Photos, and Julia + Flux Dataset which is being used to train Images Classification Convolutional Neural Network. Julia + Gtk based Validator allows me to see the results.
Why Flux and Julia, and not Tensorflow and Python? First problem for me was creating my own streaming dataset for Tensorflow in Python. (P.S. At that time I did not know Julia at all)
Mobile app
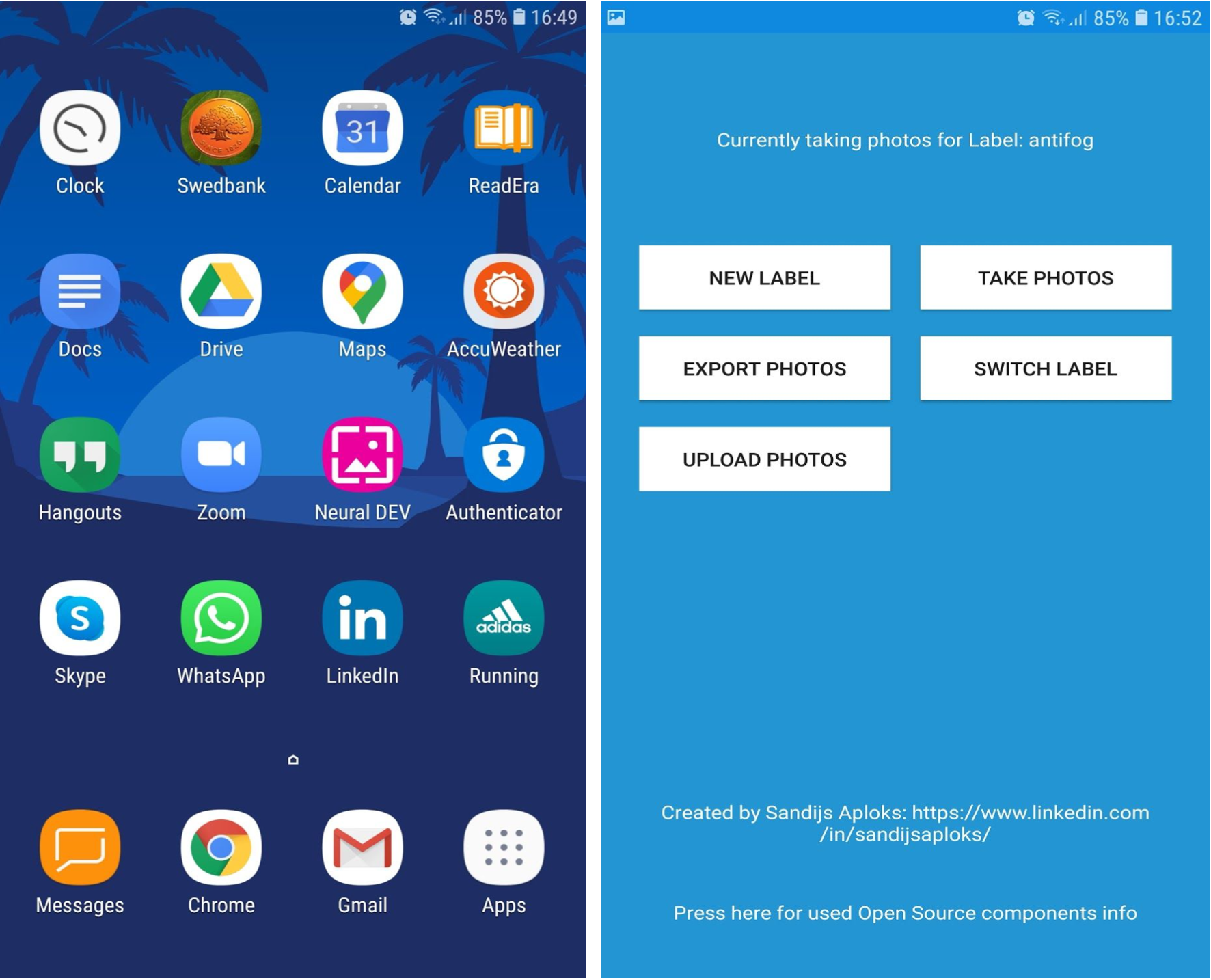

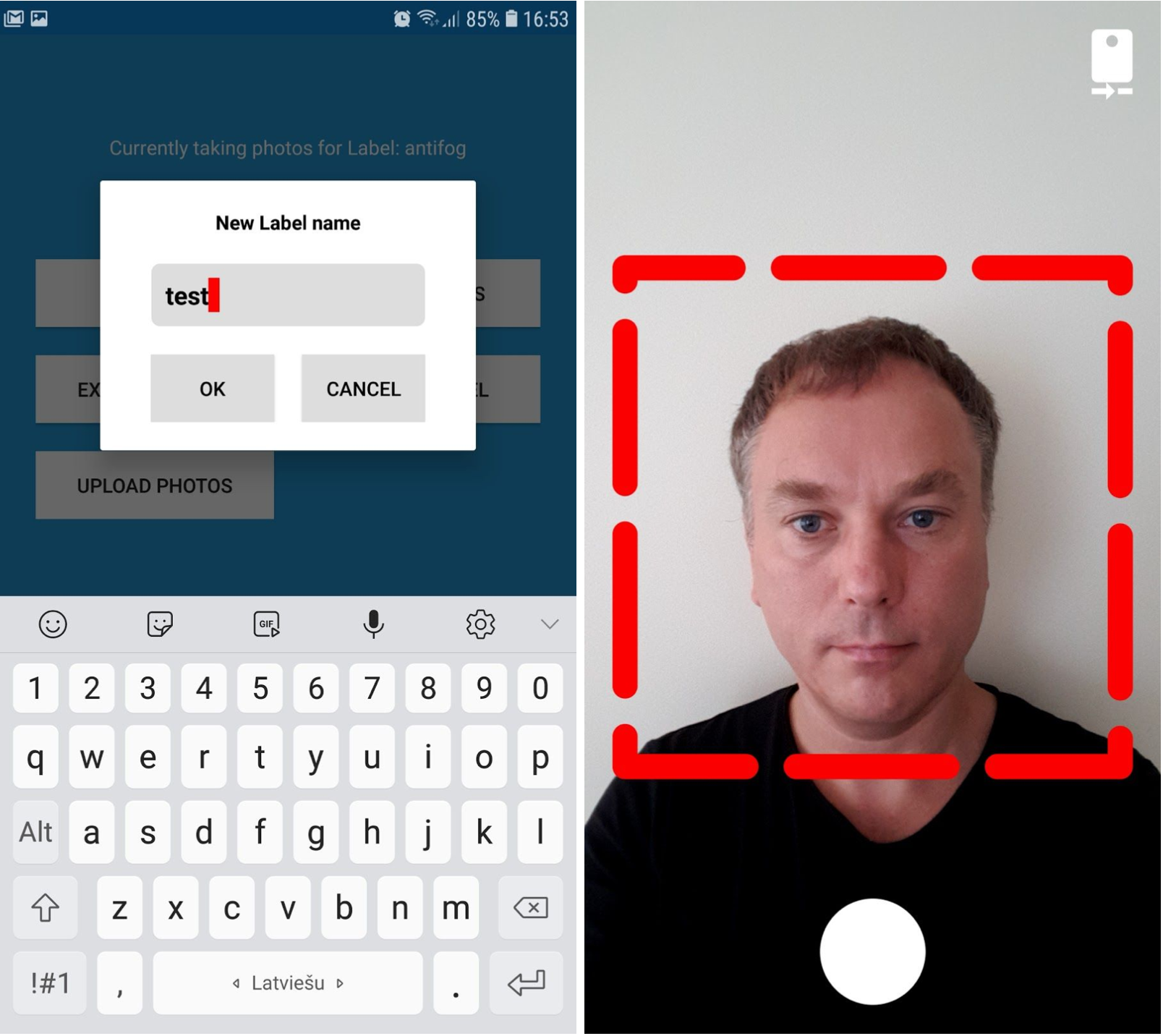
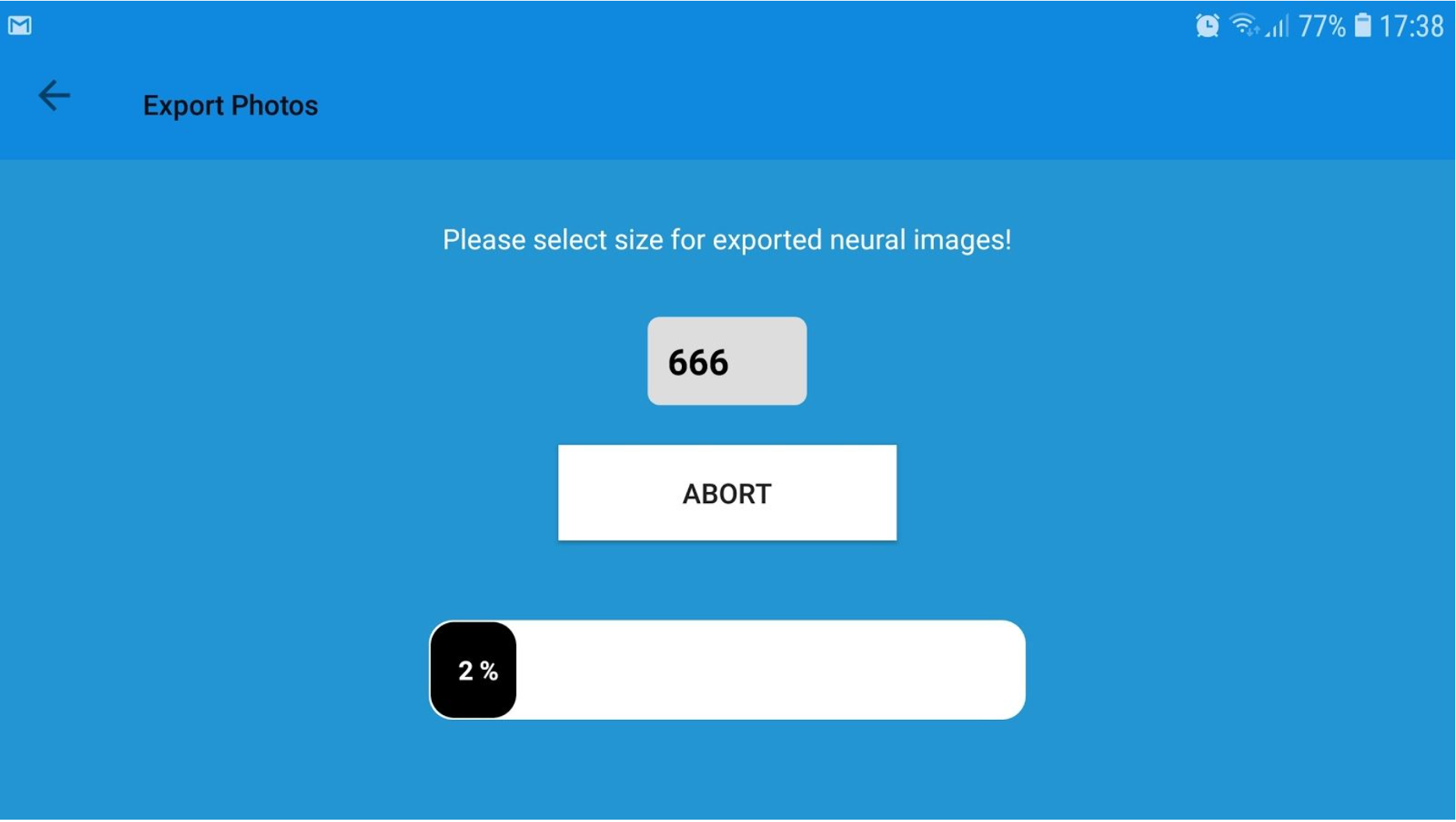
Neural Photos app:
- Takes Photos, cuts out that red square with the interesting object, and saves them as the PNG files. (Uses camera hardware buffer to not lose the data in JPEG steps)
- Launches images exporting in background which lasts for several hours on ALL processor cores
- Image rotation by 360 degrees with 20 degrees steps
- Flips and flaps of those images too
- Resizing, grayscaling
- Produced countless images saving in Grayscale Float32 little endian format for Julia Flux
- Image+Label mapping CSV file generation
- Uploads exported images to the Google Drive
In the place of traditional RxJava the app uses Kotlin Coroutines, Channels, and Flow.
When taking just something like 100 photos, generating grayscale images for neural net training takes like 2 hours to finish.
Uploading exported files to Google Drive means uploading Gigabytes of the data, and it takes a lot of time as well.
The Phone gets really hot, therefore I experimented with “slowdown” when the temperature rises.
In result this app is for people who know what they are doing and are ready for a hot phone in their pocket.
The app allows freedom in hunting down realistic photos to train some labels recognition like you will never be able by using public datasets.
The app allows total control over your dataset so that you can exclude the possibility of the hackers ruining public datasets.
The example here are a few people's comments about public audio recognition datasets oddities which could be related only to clinically angry hackers attacks...
The app could also be used to every day feed in data in distributed neural networks training clusters. (That Tensorflow thing and soon Julia Flux thing to make training huge neural networks faster and more practical)
Datasets
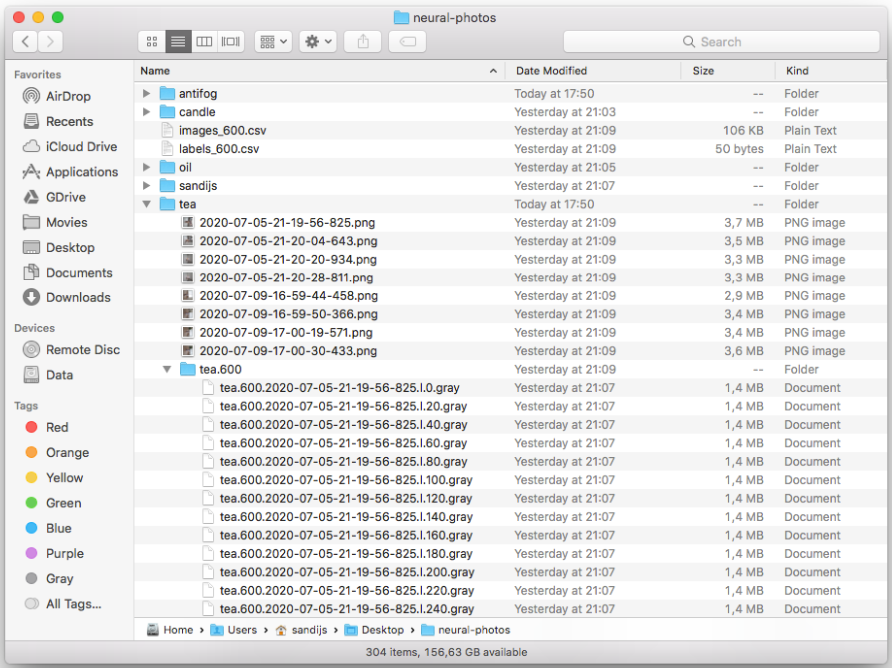
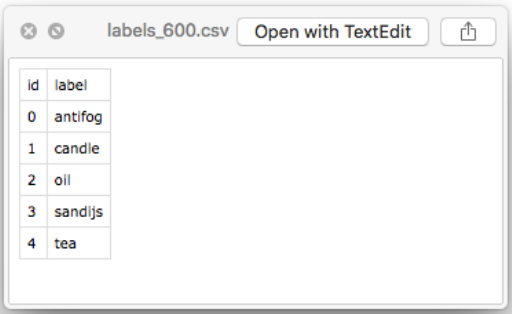
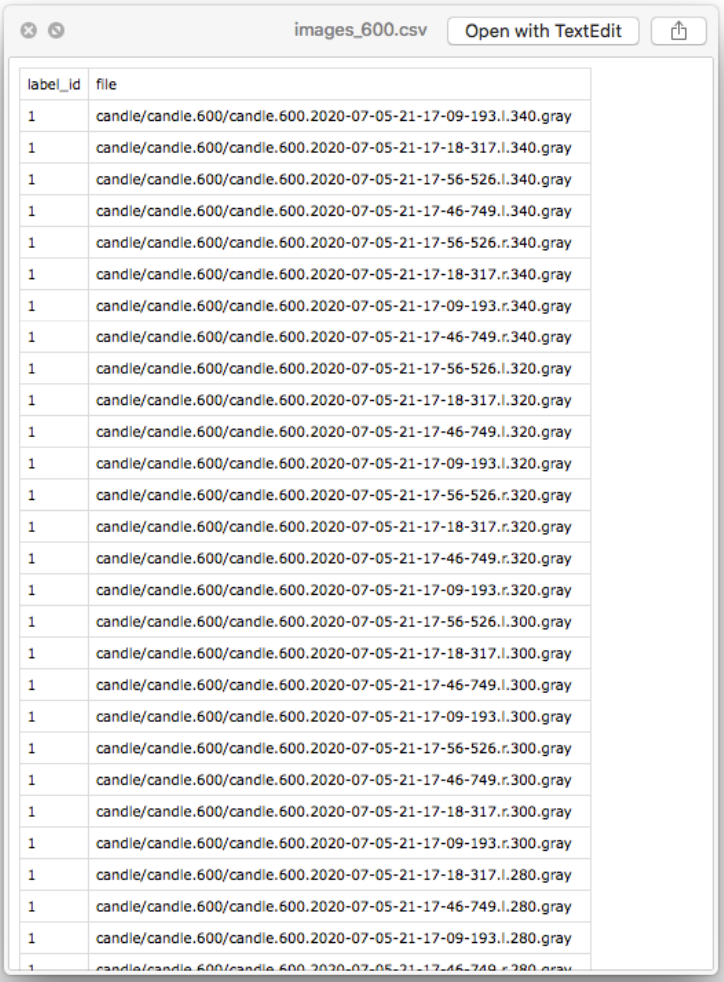
Image Classification Convolutional Neural Network training program:
- Has its own Dataset like MNIST, CIFAR, Fashionista, which knows how to use those CSV files and exported .gray files.
- The Dataset loads the data in iterations, which allows having Petabytes of the data in the Dataset, if needed. Not like MNIST which loads all the data in memory, and only then feeds it by portions into the neural network training mechanism.
- As the data has been processed on the mobile phone, there is no need to do heavy computations on the Cloud.
- It is written in Julia programming language and uses the Flux framework. Judging by several stats, and the speed of Julia, it's a better choice than Python and Tensorflow.
- Dataset can work on 600x600, 1024x1024 pictures, for example - depending on what size pictures you have exported for it's training.
Validator
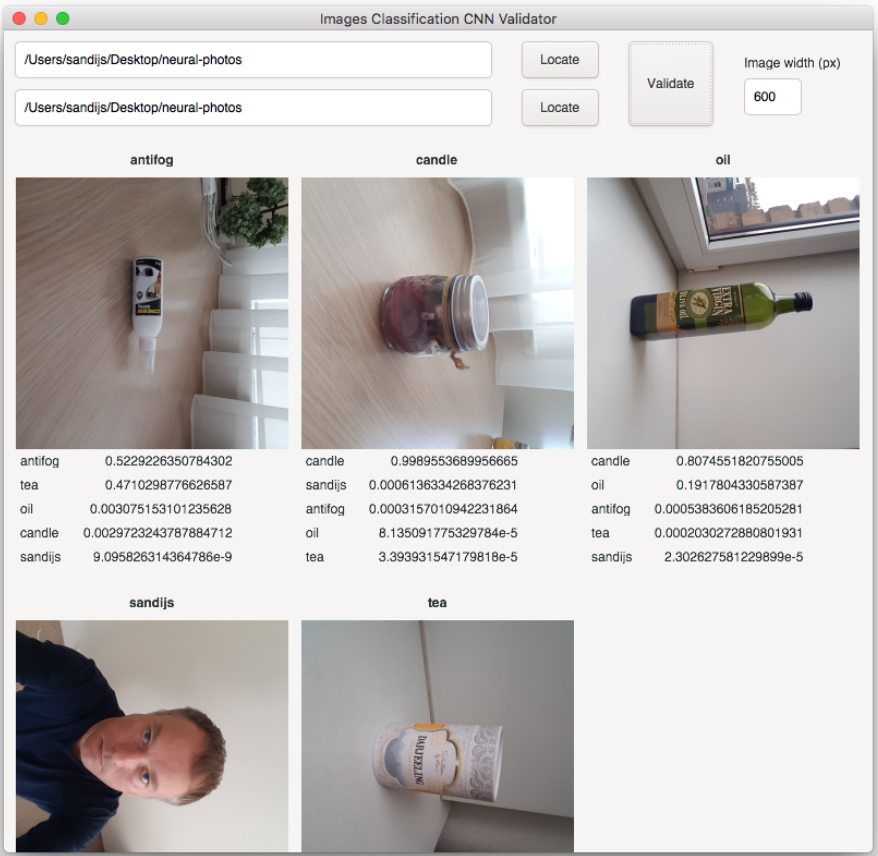
Impressions
Coroutines in Kotlin are a mechanism to use all mobile phone processor cores in parallel thus making some processes happen faster.
One can achieve that same with RxJava or Threads as well. However, in the case of Coroutines, Channels will allow easy coordinate parallel processes intelligently, not just launch them.
Kotlin JVM Coroutines are not Golang Goroutines, or Julia Tasks which could even be launched on the computers cluster, not just a single node. Still, they allow achieving a lot of cool things.
- Kotlin Coroutines on the mobile phone are not suitable for the tasks which last several hours in the background, as the phone gets so hot, and the battery gets empty really fast.
- Kotlin Coroutines on the mobile phone are not suitable to perform massive networking operations in parallel as mobile networks limit your upload capacity.
- Kotlin Coroutines on the mobile phone are suitable to make some short processes happen faster.
